大型语言模型(LLMs)如GPT-4、Claude和Llama等已经展示了令人瞩目的能力,这些模型不仅能够生成流畅的文本,还能在各种任务中表现出色,如翻译、摘要、问答等。尽管这些模型在许多方面表现出色,它们在逻辑推理,特别是条件推理和模态推理方面的能力仍然存在争议。条件推理和模态推理是逻辑学和认知科学中的核心研究领域。条件推理,即“如果…那么…”的推理形式,是人类思维中最基本的逻辑结构之一。例如,“如果下雨,那么地面会湿”就是一个典型的条件推理。模态推理则涉及“可能”、“必须”等模态词的使用,这些词语表达了不同的可能性和必然性。例如,“他可能在家”或“她必须完成作业”就是模态推理的例子。
在逻辑学中,条件推理和模态推理被广泛研究,因为它们涉及到逻辑连接词和模态运算符的精确定义和使用。经典逻辑中的材料条件分析(material conditional analysis)和模态逻辑中的可能世界语义(possible worlds semantics)是研究这些推理形式的主要方法。材料条件分析认为,“如果p,那么q”在p为假或q为真时为真,而可能世界语义则通过量化可能世界来解释模态词的含义。
在认知科学中,条件推理和模态推理被认为是人类认知能力的重要组成部分。研究表明,人类在日常生活中频繁使用这些推理形式来进行计划、决策和问题解决。例如,当我们考虑“如果我明天早起,我就能赶上早班车”时,我们实际上是在进行条件推理。同样,当我们说“他可能已经离开了”时,我们是在进行模态推理。
7 月 4 日自加利福尼亚大学伯克利分校、纽约大学和麻省理工学院的研究团队发表修订版论文《Conditional and Modal Reasoning in Large Language Models》,论文的主要研究问题是当前最先进的LLMs在处理条件推理和模态推理任务时,能否做出与人类一致的判断?具体来说,他们希望回答以下几个问题:
- LLMs在处理涉及条件句和模态词的推理任务时,表现如何?
- LLMs在这些任务中是否存在逻辑不一致或错误判断?
- 不同的提示方法(如零样本提示、少样本提示和链式思维提示)对LLMs的推理能力有何影响?
- LLMs在逻辑推理任务中的表现与其他基准测试(如Chatbot Arena、MMLU和GSM8K)有何关系?
通过回答这些问题,研究团队希望揭示LLMs在条件推理和模态推理方面的能力和局限,为未来的模型改进和应用提供参考。团队三位学者的合作结合了逻辑学、哲学和计算机科学的跨学科视角,为论文的研究提供了坚实的理论基础和技术支持。
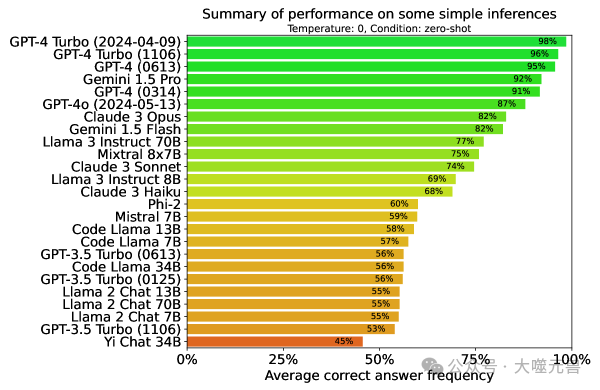
图1:对实验结果(第4节)中讨论的简单逻辑推理模式的性能总结 。猜测准确率为 50%。较大的模型通常表现更好,大多数模型在此任务中表现出明显的弱点。
逻辑推理是人类认知的重要组成部分,它涉及从一个或多个前提推导出结论的过程。在哲学中,逻辑推理被视为一种严格的思维方式,其有效性仅依赖于逻辑词的含义,如“和”、“或”、“不”、“如果”、“必须”、“可能”等。逻辑推理的有效性意味着,如果前提为真,结论必然为真,无论前提和结论中的非逻辑词如何理解(Tarski, 1936)。
这种严格的逻辑推理与日常生活中的推理有所不同。在日常生活中,人们常常进行各种推理,这些推理不仅依赖于逻辑词的含义,还涉及对世界知识和背景信息的理解。例如,“A在B的左边,因此B在A的右边”在逻辑上并不总是有效,因为其正确性依赖于“左”和“右”的具体含义。然而,“A在B的左边,因此有东西在B的左边”则是逻辑有效的,因为其正确性仅依赖于逻辑词“有东西”的含义。
在大模型(LLMs)的研究中,逻辑推理被广泛应用于评估模型的推理能力。LLMs如GPT-4、Claude和Llama等,已经展示了在生成流畅文本和处理复杂任务方面的强大能力。然而,评估这些模型在逻辑推理任务中的表现,对于理解它们的推理能力和改进模型具有重要意义。
逻辑推理任务通常包括多步推理和单步推理。多步推理需要从前提到假设的证明过程,而单步推理则关注基本的推理模式,如“如果p,那么q;非q;因此,非p”(Modus Tollens)。研究表明,LLMs在多步推理任务中表现出一定的能力,但在识别基本推理模式方面仍存在显著差距(Tafjord et al., 2020; Tian et al., 2021)。模态运算符如“必须”和“可能”在逻辑学中被成功地建模为对可能世界的量化。例如,“必须下雨”表示在所有可能的世界中都在下雨,而“可能下雨”表示在某些可能的世界中在下雨。这种解释方法产生了相应的模态逻辑,其细节取决于如何获得可能世界的域(Kripke, 1963; Kratzer, 1981)。
模态逻辑的研究进展使得我们能够更好地理解和分析模态运算符的逻辑性质。例如,模态逻辑可以帮助我们分析“可能”和“必须”之间的关系,以及它们在不同上下文中的使用方式。这对于理解自然语言中的模态表达具有重要意义。
条件运算符“如果…那么…”也通过可能世界语义进行分析。在经典逻辑中,“如果p,那么q”被视为材料条件,其在p为假或q为真时为真。然而,这种处理方式被广泛认为不适用于自然语言中的“如果”。例如,根据材料条件分析,“如果学生努力学习,那么她不会失败”将意味着“每个学生都会努力学习”,显然这并不符合我们的直觉(Stalnaker, 1968)。
相反,条件运算符通常被视为一种受限的模态运算符,表示在所有p世界中,q为真。这种解释方法产生了相应的条件逻辑,其细节取决于哪些p世界在域中,以及其他连接词和运算符的解释方式(Stalnaker, 1968; Lewis, 1973b)。
材料条件分析和模态分析在处理条件句时存在显著差异。材料条件分析认为,“如果p,那么q”在p为假或q为真时为真,而模态分析则认为,“如果p,那么q”表示在所有p世界中,q为真。尽管材料条件分析在形式逻辑中具有简洁性和一致性,但它在处理自然语言中的条件句时往往不符合我们的直觉。
例如,根据材料条件分析,“如果下雨,那么地面湿”在下雨为假时为真,即使地面实际上是干的。然而,模态分析则认为,这种条件句在所有下雨的世界中,地面都是湿的,更符合我们的直觉和实际经验。因此,模态分析在处理自然语言中的条件句时,通常被认为更为准确和有效。自然语言推理(NLI)是一种评估模型理解和推理能力的任务格式。在NLI任务中,模型需要判断一个前提和一个假设之间的关系,具体来说,前提是否蕴涵、矛盾或与假设无关。NLI任务通常基于常识推理,而不是严格的逻辑推理(Bowman et al., 2015; Williams et al., 2018)。
NLI任务的评估方法通常包括准确率、召回率和F1分数等指标。这些指标用于衡量模型在不同推理任务中的表现,帮助研究人员评估和改进模型的推理能力。
本研究与传统的NLI任务有所不同。首先,本研究专注于单步逻辑推理,而不是一般的常识推理。我们关注的是模型在处理基本逻辑推理模式时的表现,如Modus Tollens、Modus Ponens等,而不是复杂的多步推理或常识推理任务。
其次,本研究引入了哲学、语言学和逻辑学中关于条件句和模态的复杂方法。这些方法帮助我们更准确地评估模型在处理条件句和模态词时的逻辑推理能力,而不仅仅是基于常识和背景知识的推理。
在本研究中,我们测试了25个大型语言模型(LLMs),这些模型包括开源和闭源的不同版本。具体来说,这些模型涵盖了Anthropic、Google和OpenAI等公司的产品,以及一些本地运行的模型。测试的模型包括但不限于以下几种:
GPT-4系列:包括GPT-4 Turbo(2024-04-09)、GPT-4 Turbo(1106)、GPT-4(0613)、GPT-4(0314)和GPT-4o(2024-05-13)。
Claude系列:包括Claude 3 Opus、Claude 3 Sonnet和Claude 3 Haiku。
Llama系列:包括Llama 3 Instruct 70B、Llama 3 Instruct 8B、Llama 2 Chat 13B、Llama 2 Chat 70B和Llama 2 Chat 7B。
其他模型:如Gemini 1.5 Pro、Gemini 1.5 Flash、Mixtral 8x7B、Phi-2、Mistral 7B、Code Llama 13B、Code Llama 7B、Code Llama 34B、GPT-3.5 Turbo(0613)、GPT-3.5 Turbo(0125)、GPT-3.5 Turbo(1106)和Yi Chat 34B。
这些模型的选择旨在涵盖不同的架构和训练方法,以便全面评估LLMs在条件和模态推理任务中的表现。
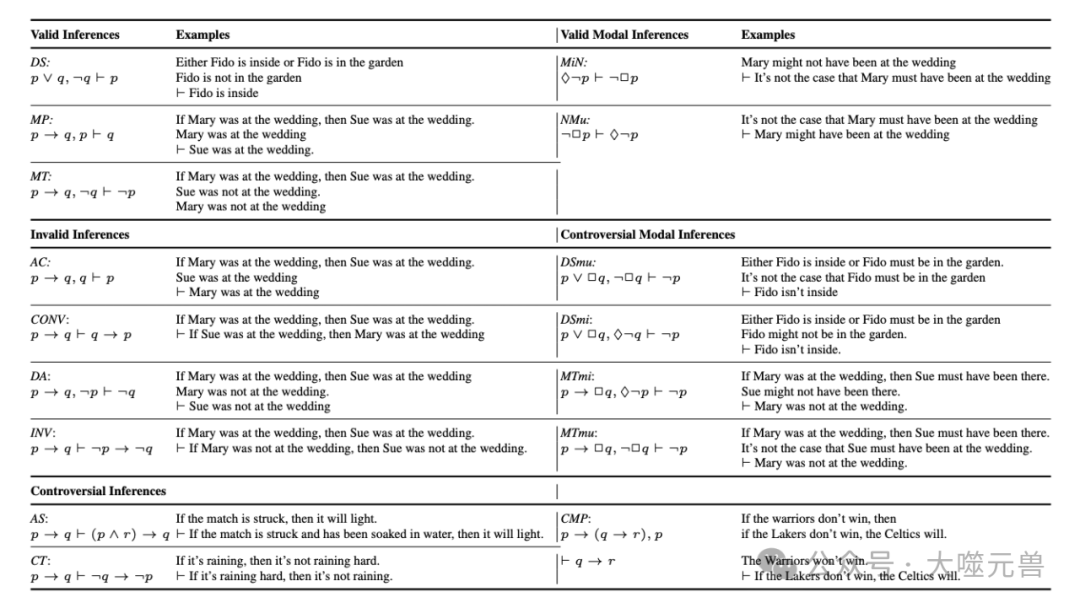
表1:检验的推论;p、 q表示模态/条件自由命题,−表示“not”,∧表示“or”,→表示“if…”。然后“可能”,✷表示“必须”。φ1, . . . , φn⊢ψ是从前提φ1,φn到结论ψ。图1总结了所有且仅在没有模态的无争议推理上的成功。
对于Anthropic、Google和OpenAI的模型,我们通过各自的API进行测试。这些API提供了访问模型的接口,使我们能够在云端运行推理任务。对于本地模型,我们使用了LM Studio在Apple M2 Ultra Mac Studio上创建本地推理服务器。所有本地模型都是在Hugging Face上提供的Q6_K GGUF格式的6位量化版本。这种设置确保了我们能够在本地环境中高效地运行推理任务,同时保持模型的性能和准确性。
为了评估LLMs的推理能力,我们创建了一个包含多个推理模式的问题库。这些推理模式包括经典的逻辑推理模式,如Modus Tollens(MT)、Modus Ponens(MP)、析取消去(DS)等。每个推理模式的问题库包含多个实例,以便全面测试模型在不同推理任务中的表现。
为了确保模型的推理能力评估不受世界知识的影响,我们为每个推理模式设计了范例实例和无意义谓词实例。例如,对于Modus Tollens(MT),我们设计了以下范例实例:“如果玛丽参加了婚礼,那么苏参加了婚礼;苏没有参加婚礼;因此,玛丽没有参加婚礼。”此外,我们还使用Claude 2创建了19个额外实例和20个无意义谓词的实例,如:“如果flugel被blimmed,那么flugel被zargled;flugel没有被zargled;因此,flugel没有被blimmed。”这些无意义谓词实例确保了模型的推理判断基于逻辑形式,而不是具体的世界知识。
为了测试前提顺序对推理结果的影响,我们为每个推理模式设计了前提顺序交换的版本。例如,对于Modus Tollens(MT),我们设计了前提顺序交换的版本(MTx),即交换前提的顺序。此外,我们还设计了无意义谓词和前提顺序交换的组合版本(ox),以全面评估模型在不同前提顺序下的推理能力。
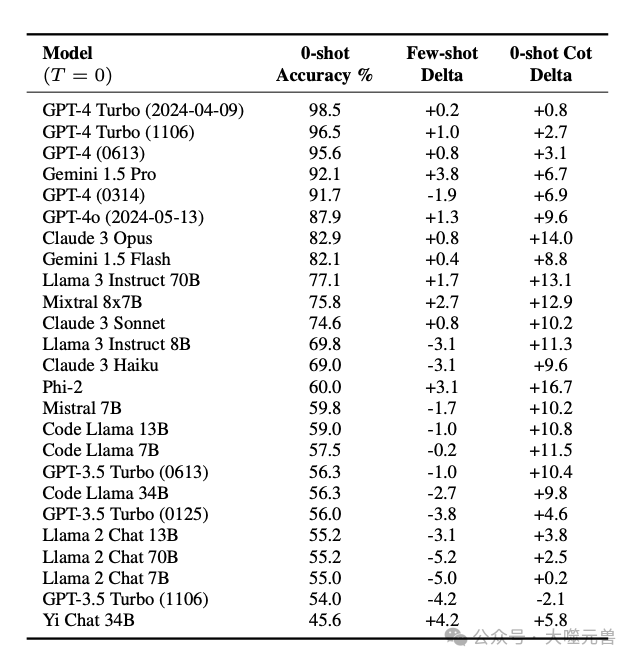
在评估过程中,我们对每个推理模式的问题实例和每个LLM进行了多次测试,设置了不同的温度和提示条件。具体来说,我们在温度为0和1的情况下进行了测试,并使用了零样本、少样本和零样本链式思维提示条件。温度设置为0时,模型的输出更为确定,而温度设置为1时,模型的输出更具随机性。提示条件包括零样本提示(直接给出问题)、少样本提示(提供几个示例)和零样本链式思维提示(引导模型逐步推理)。
为了确保我们的评估结果具有可靠性,我们进行了相关性分析和词语敏感性测试。具体来说,我们计算了模型在无意义谓词实例和有意义谓词实例上的回答频率之间的皮尔逊相关系数。高相关性表明模型的推理判断主要基于逻辑形式,而不是具体实例的特征。此外,我们测试了使用不同词语(如“推断”、“得出结论”等)对结果的敏感性,发现使用不同词语对结果影响不大。
通过这些评估方法,我们能够全面、准确地评估LLMs在条件和模态推理任务中的表现,为理解和改进模型提供了重要的参考依据。
在逻辑推理中,材料条件分析和模态分析是两种主要的方法。材料条件分析认为,“如果p,那么q”在p为假或q为真时为真,而模态分析则认为,“如果p,那么q”表示在所有p世界中,q为真。在本研究中,我们特别关注了两种推理模式:CT(Conditional Transitivity)和AS(Antecedent Strengthening)。
根据材料条件分析,CT推理模式是有效的。然而,模态分析和直觉反例表明,CT推理模式实际上无效。例如,从“如果下雨,那么不下大雨”推导出“如果下大雨,那么不下雨”显然是不合理的,但如果CT有效,这种推理模式就会成立(Stalnaker, 1968)。
类似地,AS推理模式在材料条件分析中是有效的,但模态分析和直觉反例表明,AS推理模式实际上无效。例如,从“如果火柴被划燃,它会点燃”推导出“如果火柴被划燃且被浸泡在水中,它会点燃”显然是不合理的(Stalnaker, 1968)。
在我们的实验中,LLMs在拒绝CT和AS推理模式方面表现出与人类判断一致的倾向。这表明,LLMs在处理自然语言中的条件句时,并不像材料条件那样进行推理,而是更接近于模态分析。这一发现强调了在评估LLMs的推理能力时,不应简单地假设材料条件分析的有效性,否则可能会错误地认为模型在这些情况下犯了错误。
我们测试了多种涉及模态与条件句或析取交互的推理模式。这些推理模式特别有趣,因为哲学和逻辑学的研究表明,替换模态句子可以改变推理模式的有效性。例如,析取消去(DS)在布尔句子中是有效的,但在模态句子中则不一定有效(DSmu)。类似地,否定前件(MT)在布尔句子中是有效的,但在模态句子中则不一定有效(MTmu)。
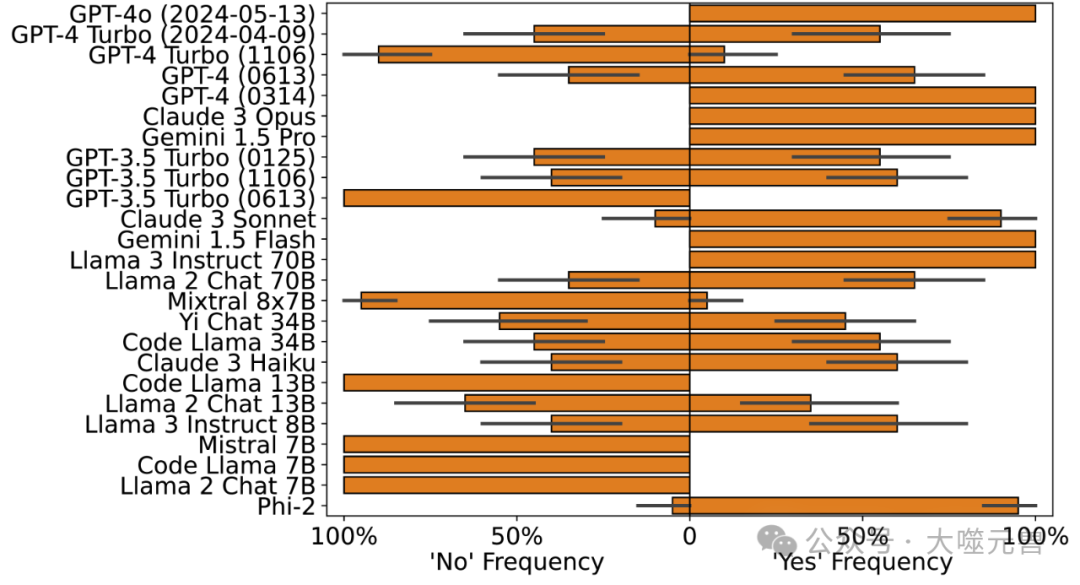
图2:MTmu(上图)和MTmi(下图)的零样本响应显示了许多模型的不一致性。
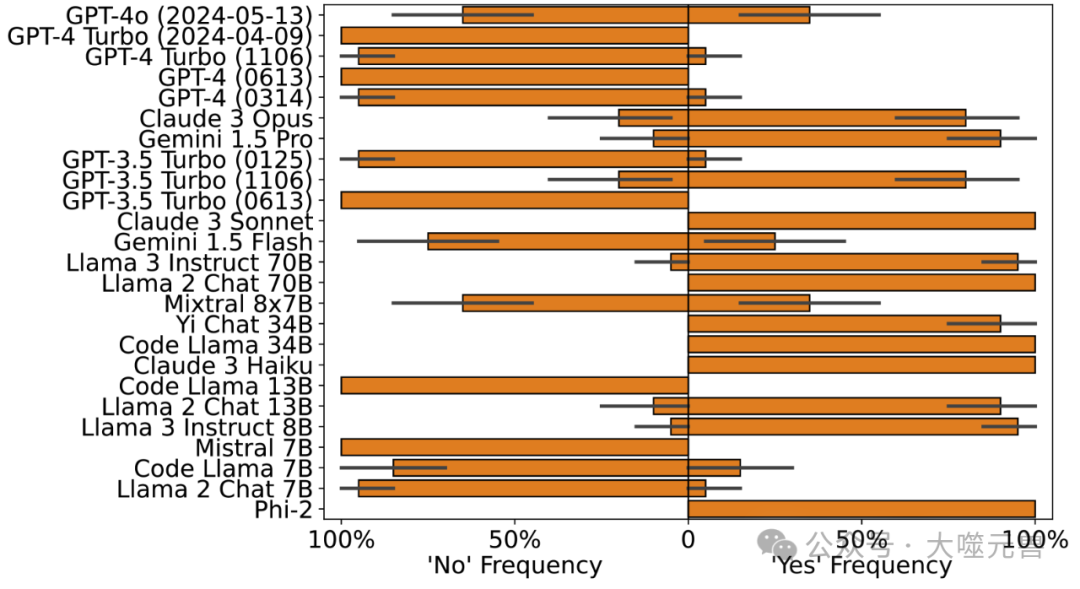
图 3:DSmu(上图)和 DSmi(下图)的零样本响应显示许多模型存在不一致。
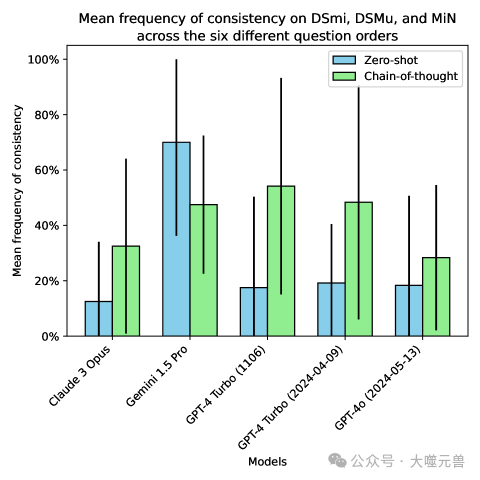
图4:当我们按某种顺序同时询问领先模型有关 DSmu、MiN 和 DSmi 的问题时,联合一致的响应百分比。较大的标准差(误差线)表明对问题顺序具有很强的敏感性,这是非常不理想的。
我们的研究发现,许多LLMs在这些复杂推理模式上表现出过度泛化的倾向。例如,尽管人类能够识别MTmu、DSmu和CMP(Conditional Modus Ponens)推理模式的无效性,许多LLMs却不能。这表明,LLMs在处理这些复杂推理模式时,往往会从简单的布尔情况过度泛化到更复杂的情况。
在我们的实验中,我们发现一些模型在拒绝MTmi(模态否定前件)时表现出类似人类的判断,但同时接受MTmu,这在逻辑上是不一致的。这种不一致性表明,LLMs在处理模态和条件句的交互时,可能会出现逻辑错误。此外,我们还发现,即使是表现最好的模型,在处理CMP推理模式时,仍然会以高频率接受其有效性,这与人类判断相悖。
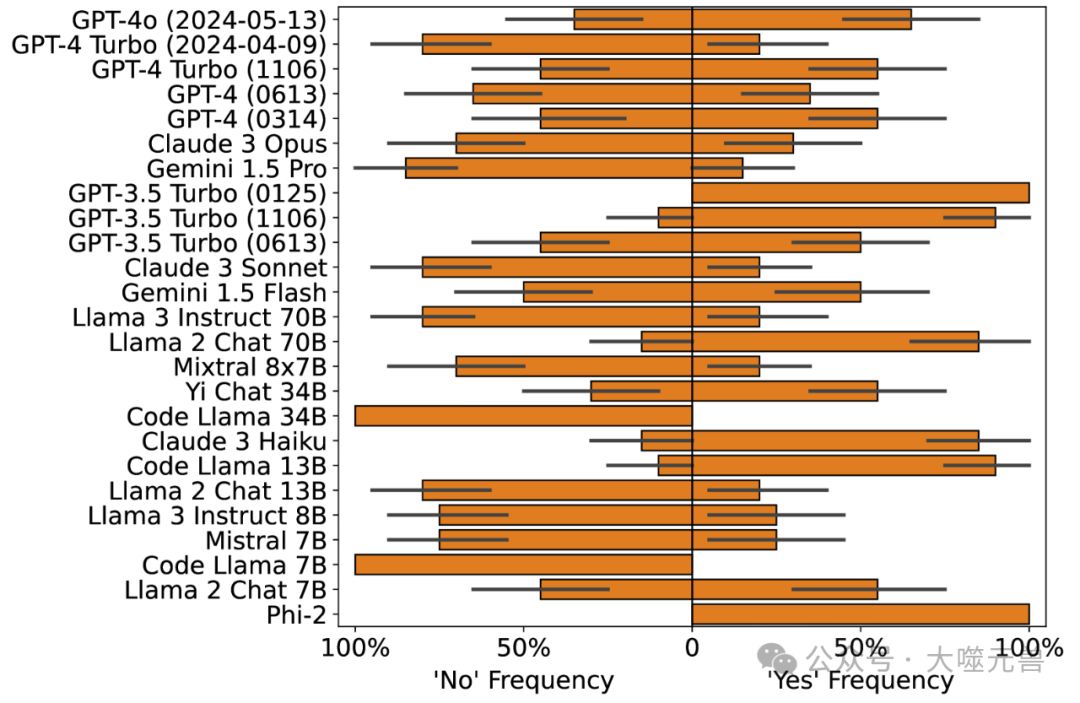
图5:CMP、零样本(上图)和思维链(下图)的反应;LLM被问及推理是否保留了可能性,即当p→(q→r)是确定的并且p是可能的时,如果q→r必须是可能的。
为了将我们的逻辑推理任务与LLMs评估的广泛领域进行比较,我们将模型在我们的基准测试(非争议性推理)上的表现与Chatbot Arena(通用辅助)、MMLU(领域知识)和GSM8K(数学推理)等流行基准测试进行了比较。结果显示,我们的结果与这些基准测试的结果高度相关。
这种高相关性支持了逻辑推理能力与数学推理能力及领域通用能力相关的假设。这表明,逻辑推理能力不仅与数学推理能力相关,还与模型的整体能力密切相关。未来的研究可以进一步探讨这种因果关系:提高逻辑推理能力是否也能提高模型的其他推理和辅助能力。
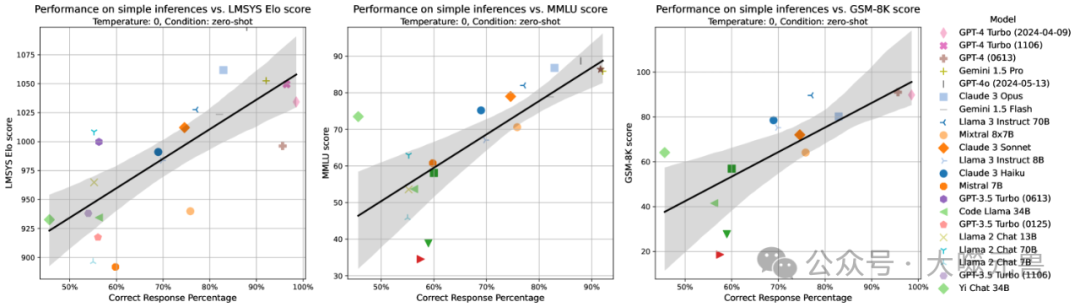
图6:我们的评估结果(零样本)与 LMSYS Elo 评分、MMLU 分数和 GSM8k 分数的相关性。相关性分别为 0.74、0.77 和 0.72。所有 p 值均小于 0.01。
在本研究中,我们测试了25个大型语言模型(LLMs)在条件和模态推理任务中的表现。总体而言,较大的模型在这些推理任务中表现更好,这与我们在过去几年中对LLMs的认识一致。具体来说,GPT-4系列模型在大多数推理任务中表现优异,特别是在零样本链式思维提示条件下,表现尤为突出。
即使是最先进的模型在某些推理任务中仍然表现出不一致和反直觉的推理行为。例如,尽管GPT-4系列模型在许多推理模式上表现出色,但在处理涉及模态和条件句交互的复杂推理模式时,仍然会出现逻辑不一致的情况。这表明,尽管LLMs在许多方面已经接近人类水平,但在处理某些复杂推理任务时仍存在显著差距。
链式思维提示(Chain-of-Thought,CoT)是一种引导模型逐步推理的方法。在我们的实验中,链式思维提示显著提高了模型在推理任务中的表现。具体来说,GPT-4系列模型、Gemini 1.5 Pro和Claude 3 Opus在使用链式思维提示时,几乎达到了完美的准确率(98.6%以上),而Llama 3 70B也能够达到90%以上的准确率。
这种提示方法的有效性表明,通过引导模型逐步推理,可以显著提高其在复杂推理任务中的表现。这一发现对于未来的模型改进具有重要意义,因为它表明,通过适当的提示和引导,可以帮助模型更好地理解和处理复杂的推理任务。
尽管链式思维提示在许多情况下显著提高了模型的表现,但我们仍然识别出了一些不一致和反直觉的推理行为。例如,在处理MTmu(模态否定前件)和DSmu(模态析取消去)等复杂推理模式时,许多模型表现出过度泛化的倾向,即从简单的布尔情况过度泛化到更复杂的模态情况。
此外我们还发现,即使是表现最好的模型,在处理CMP(条件推理模式)时,仍然会以高频率接受其有效性,这与人类判断相悖。这些不一致和反直觉的推理行为表明,LLMs在处理某些复杂推理任务时,可能会出现逻辑错误和判断失误。未来的研究可以进一步探讨LLMs与人类受试者在推理任务中的行为比较。尽管本研究报告了专家人类判断,但实验性人类受试者的判断可能会展示出与LLMs类似或不同的错误。这种比较可以帮助我们更好地理解LLMs在推理任务中的表现,并为改进模型提供参考。
研究主要集中在一些经典的推理模式,如Modus Tollens、Modus Ponens和析取消去等。未来的研究可以探索更多的推理模式,特别是涉及模态、条件句以及其他逻辑运算符的推理模式。例如,广义量词、态度谓词和程度结构等推理模式也值得进一步研究。
模态和条件推理与其他推理主题,如概率推理、因果模型和心理模拟等,有着天然的联系。未来的研究可以探讨模态和条件语言在这些推理主题中的应用。例如,模态和条件语言可以提供另一种视角来研究LLMs和人类在概率推理和因果推理中的表现。
本研究揭示了LLMs在条件和模态推理任务中的表现和局限,为未来的模型改进和应用提供了重要的参考。通过进一步探索这些推理模式的复杂性,以及与其他推理主题的联系,我们可以更好地理解和改进LLMs的推理能力。(END)
参考资料:https://arxiv.org/pdf/2401.17169

波动世界(PoppleWorld)是噬元兽数字容器的一款AI应用,是由AI技术驱动的帮助用户进行情绪管理的工具和传递情绪价值的社交产品,基于意识科学和情绪价值的理论基础。波动世界将人的意识和情绪作为研究和应用的对象,探索人的意识机制和特征,培养人的意识技能和习惯,满足人的意识体验和意义,提高人的自我意识、自我管理、自我调节、自我表达和自我实现的能力,让人获得真正的自由快乐和内在的力量。波动世界将建立一个指导我们的情绪和反应的价值体系。这是一款针对普通人的基于人类认知和行为模式的情感管理Dapp应用程序。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
